Deep Learning - An Introduction
Deep learning is one of the most influential technologies in modern computer science, and over the last decade it has transformed the way machines interact with language, images, audio, video, and even scientific research. Today, when people talk about artificial intelligence systems that can recognize faces, translate languages, generate images, drive vehicles, or answer questions intelligently, deep learning is usually working behind the scenes.
However, beginners often encounter a major problem when they first enter this field. Terms like artificial intelligence, machine learning, neural networks, representation learning, GPU training, feature engineering, and deep neural networks are frequently used together, and this creates confusion about how all these concepts are related.
Relationship Between AI, Machine Learning, and Deep Learning
Before understanding deep learning, it is important to understand the hierarchy of concepts surrounding it. Many beginners use terms like Artificial Intelligence, Machine Learning, and Deep Learning interchangeably, but they are not exactly the same thing.
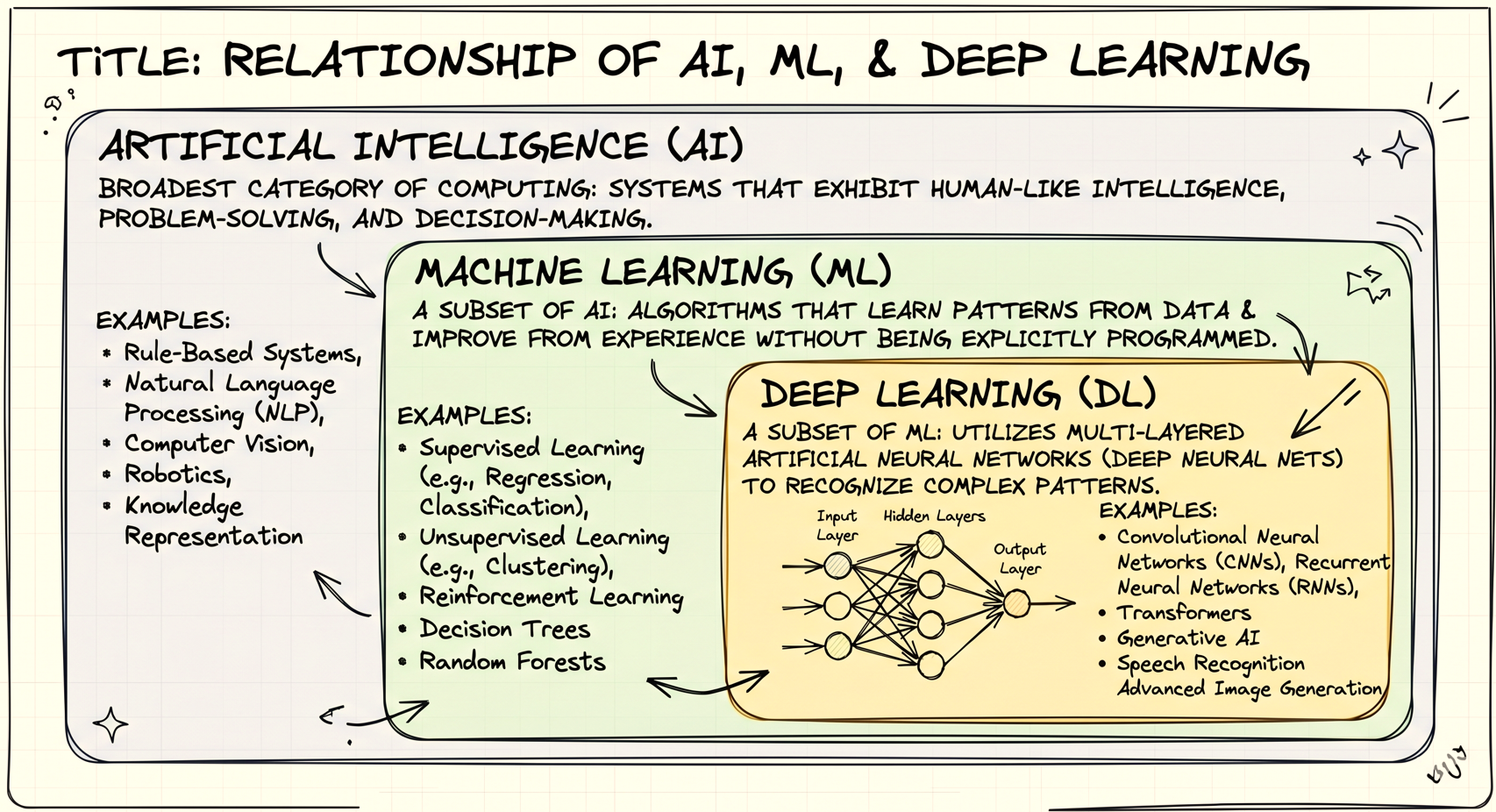
Artificial Intelligence (AI)
Artificial Intelligence, commonly called AI, is the broad field of computer science that focuses on building systems capable of performing tasks that normally require human intelligence. These tasks may include reasoning, problem solving, language understanding, image recognition, decision making, and learning from experience. The main goal of AI is to create machines that can behave intelligently and assist humans in solving complex problems.
A simple definition of AI is:
Artificial Intelligence is the field of creating intelligent machines that can simulate human thinking and decision-making abilities.
AI is the largest umbrella term among all related technologies. Many technologies such as robotics, expert systems, machine learning, and deep learning fall under the domain of Artificial Intelligence.
For example, when a virtual assistant understands voice commands or when a navigation system suggests the fastest route, AI is working behind the scenes.
Machine Learning (ML)
Machine Learning is a subfield of Artificial Intelligence where computers learn patterns directly from data instead of being explicitly programmed with fixed rules. In traditional programming, developers manually write instructions for every scenario. In machine learning, however, the system studies examples and automatically discovers relationships within the data.
A simple definition of Machine Learning is:
Machine Learning is a branch of AI that enables systems to learn from data and improve their performance without being explicitly programmed for every task.
Suppose we provide a machine learning system with data containing house features and house prices. The algorithm studies the relationship between these inputs and outputs, and after learning from enough examples, it can predict the price of a new house.
Machine learning algorithms are widely used in applications such as:
- spam email detection
- recommendation systems
- fraud detection
- stock prediction
- customer analytics
Traditional machine learning systems usually depend heavily on feature engineering, where developers manually select important features from the data before training the model.
Deep Learning (DL)
Deep Learning is a specialized branch of Machine Learning that uses neural networks inspired by the structure of the human brain. Unlike traditional machine learning, deep learning systems can automatically learn useful features directly from raw data, making them extremely powerful for complex tasks such as image recognition, speech processing, and language understanding.
A simple definition of Deep Learning is:
Deep Learning is a subset of Machine Learning that uses multi-layered neural networks to automatically learn complex patterns from large amounts of data.
The term “deep” comes from the presence of multiple hidden layers inside neural networks. These layers gradually learn different levels of information from the data. For example, in image recognition, early layers may detect edges and textures, while deeper layers may identify complete objects such as faces, animals, or vehicles.
Today, deep learning powers many modern technologies, including:
- self-driving cars
- facial recognition systems
- chatbots and language models
- medical image analysis
- voice assistants
- image generation systems
Deep learning is considered one of the most important technological advancements in modern Artificial Intelligence because it allows machines to learn highly complex patterns with remarkable accuracy.
What is Deep Learning?
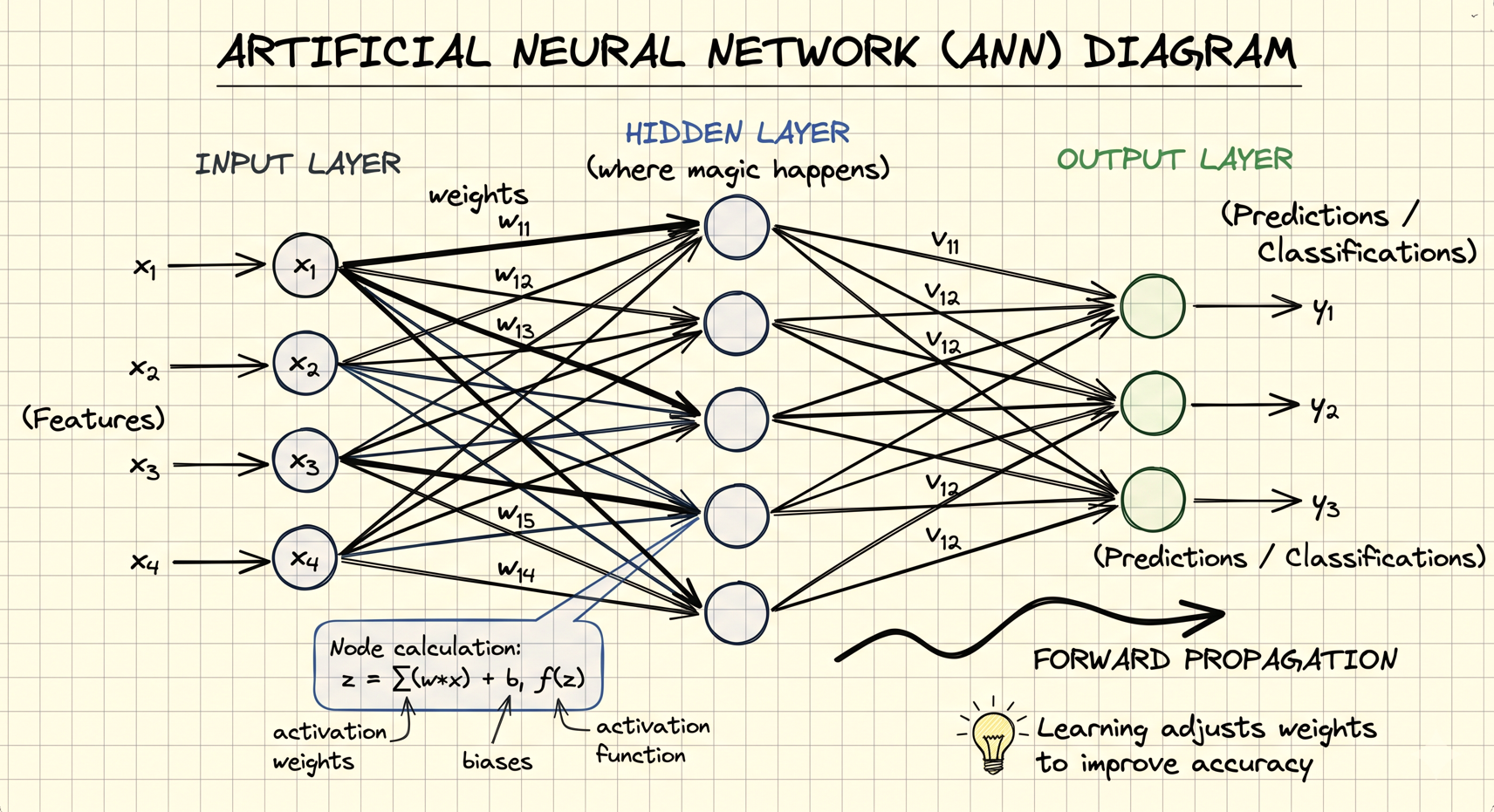
A Neural Network, more formally called an Artificial Neural Network (ANN), is a computational model used in Deep Learning that is inspired by the structure and working style of the human brain. It is designed to recognize patterns, learn relationships from data, and make intelligent predictions or decisions.
A simple definition of a Neural Network is:
A Neural Network is a layered system of interconnected processing units that learns patterns from data by adjusting internal connections during training.
The basic idea behind neural networks came from observing how biological neurons in the human brain communicate with each other. Although artificial neural networks are much simpler than real brains, they follow a somewhat similar concept where multiple small units work together to process information.
A neural network is generally made up of three major types of layers:
- Input Layer
- Hidden Layers
- Output Layer
The input layer receives the raw data. For example, if we are building an image classification system, the input layer receives image data in the form of pixels.
The hidden layers perform the actual learning and feature extraction. These layers gradually identify patterns inside the data. In image processing tasks, early hidden layers may detect simple features such as edges or textures, while deeper layers may identify more complex patterns like eyes, faces, or complete objects.
The output layer produces the final prediction. For example, it may predict whether an image contains a cat or a dog.
The connections between neurons contain numerical values called weights. During training, the neural network continuously adjusts these weights in order to reduce prediction errors and improve accuracy. This learning process allows the network to gradually become better at recognizing patterns.
One of the most important characteristics of neural networks is their ability to automatically learn features directly from raw data. Traditional machine learning systems often require manual feature engineering, but neural networks can discover useful patterns on their own through training.
Neural networks are widely used in modern AI systems because they are highly effective for solving complex problems involving:
- image recognition
- speech processing
- natural language understanding
- recommendation systems
- medical diagnosis
- autonomous driving
- generative AI
When a neural network contains many hidden layers, it becomes a Deep Neural Network, and the overall approach is called Deep Learning. The word “deep” refers to the depth created by multiple hidden layers working together to learn increasingly complex representations from data.
Types of Neural Networks
Neural networks are not all designed for the same kind of problem. Different architectures are created to handle different types of data such as images, text, audio, time-series data, or sequential patterns. Some neural networks are excellent at recognizing visual patterns, while others are better at understanding language, remembering sequences, or generating entirely new content. Over time, researchers developed specialized neural network architectures to solve increasingly complex problems in fields like computer vision, natural language processing, robotics, healthcare, and generative AI.
The most commonly used types of neural networks are:
- Feedforward Neural Network (FNN)
- Convolutional Neural Network (CNN)
- Recurrent Neural Network (RNN)
- Long Short-Term Memory Network (LSTM)
- Gated Recurrent Unit (GRU)
- Transformer Network
- Autoencoder
- Generative Adversarial Network (GAN)
- Radial Basis Function Network (RBFN)
- Self-Organizing Map (SOM)
- Deep Belief Network (DBN)
- Modular Neural Network
Each neural network architecture has its own strengths, limitations, and ideal use cases. Choosing the correct neural network depends heavily on the type of data being processed and the problem being solved.
Feedforward Neural Network (FNN)
A Feedforward Neural Network is the simplest and earliest type of neural network where information moves only in one direction, from the input layer to hidden layers and finally to the output layer, without looping backward. This network does not have memory and treats every input independently. Feedforward networks are mainly used for basic classification and regression problems where relationships in the data are relatively straightforward. Their major features include simple architecture, fast computation, and easy implementation, making them suitable for beginner-level neural network applications such as handwritten digit classification, basic prediction systems, and simple pattern recognition tasks.
Convolutional Neural Network (CNN)
A Convolutional Neural Network is specifically designed for processing image and visual data. CNNs use convolution layers to automatically detect important visual features such as edges, textures, shapes, and objects. One of the biggest advantages of CNNs is that they reduce the need for manual feature extraction because the network learns visual patterns automatically during training. CNNs are widely used in image classification, facial recognition, medical imaging, object detection, autonomous vehicles, and video analysis. Their key features include parameter sharing, spatial feature extraction, pooling layers, and strong performance on high-dimensional image data.
Recurrent Neural Network (RNN)
A Recurrent Neural Network is designed for sequential data where previous inputs influence future outputs. Unlike feedforward networks, RNNs contain loops that allow information to persist, giving the network a form of memory. This makes them useful for tasks involving time-series data, language modeling, speech recognition, and text generation. RNNs are capable of understanding sequences and contextual relationships, but they suffer from problems such as vanishing gradients when handling very long sequences. Their major feature is the ability to process ordered data step by step while maintaining hidden states that carry information from earlier inputs.
Long Short-Term Memory Network (LSTM)
A Long Short-Term Memory is an improved version of RNN specifically created to solve the long-term dependency problem. LSTMs use special memory cells and gates called input gates, forget gates, and output gates to selectively remember or forget information over long sequences. Because of this architecture, LSTMs can capture long-range dependencies much more effectively than standard RNNs. They are commonly used in machine translation, speech recognition, predictive text systems, stock market prediction, and sequence forecasting. Their major features include long-term memory retention, better gradient flow, and strong performance in sequential learning tasks.
Gated Recurrent Unit (GRU)
A Gated Recurrent Unit is another advanced recurrent architecture similar to LSTM but with a simpler structure and fewer gates. GRUs combine certain operations to reduce computational complexity while still maintaining the ability to capture long-term dependencies in sequential data. Because of their simpler design, GRUs often train faster than LSTMs while delivering comparable performance in many applications. GRUs are widely used in speech processing, text analysis, chatbot systems, and time-series prediction. Their important features include faster training, reduced computational cost, and efficient handling of sequential information.
Transformer Network
A Transformer is one of the most important modern neural network architectures and forms the foundation of most generative AI systems today. Transformers use a mechanism called self-attention, which allows the model to understand relationships between words or tokens regardless of their position in the sequence. Unlike RNNs, transformers process entire sequences in parallel, making training significantly faster and more scalable. Transformers are used in large language models, translation systems, chatbots, text summarization, code generation, and modern AI assistants. Their major features include parallel processing, attention mechanisms, scalability, contextual understanding, and exceptional performance in natural language processing tasks.
Autoencoder
An Autoencoder is a neural network designed to learn compressed representations of data. It consists of two main parts: an encoder that compresses the input data and a decoder that reconstructs the original data from the compressed representation. Autoencoders are mainly used for dimensionality reduction, anomaly detection, denoising images, and feature learning. One of their major strengths is the ability to learn meaningful patterns without requiring labeled data. Their key features include unsupervised learning capability, data compression, feature extraction, and noise reduction.
Generative Adversarial Network (GAN)
A Generative Adversarial Network is a powerful generative model consisting of two competing neural networks called the generator and discriminator. The generator creates fake data samples, while the discriminator tries to determine whether the generated samples are real or fake. Through this adversarial training process, GANs become capable of generating highly realistic images, videos, music, and synthetic data. GANs are commonly used in image generation, deepfakes, art generation, super-resolution imaging, and AI-based creative systems. Their major features include realistic content generation, adversarial training, high-quality synthetic outputs, and creative AI applications.
Radial Basis Function Network (RBFN)
A Radial Basis Function Network is a neural network that uses radial basis functions as activation functions. These networks are particularly effective for interpolation, classification, and function approximation problems. RBFNs usually train faster than traditional multilayer neural networks because only certain layers require adjustment during training. They are commonly used in control systems, forecasting, signal processing, and pattern classification. Their important features include fast learning speed, smooth interpolation, and strong approximation capabilities.
Self-Organizing Map (SOM)
A Self-Organizing Map is an unsupervised learning neural network used primarily for clustering and visualization of high-dimensional data. SOMs organize data into lower-dimensional maps while preserving the relationships between data points. This makes them useful for exploratory data analysis, customer segmentation, anomaly detection, and data visualization. Their major features include dimensionality reduction, clustering capability, topology preservation, and visualization of complex datasets.
Deep Belief Network (DBN)
A Deep Belief Network is a deep neural architecture composed of multiple layers of stochastic latent variables, often built using Restricted Boltzmann Machines (RBMs). DBNs were historically important in the development of deep learning because they helped improve unsupervised pretraining techniques before modern transformer architectures became dominant. They are used in feature extraction, dimensionality reduction, and pattern recognition tasks. Their key features include probabilistic learning, layered feature representation, and unsupervised pretraining capability.
Modular Neural Network
A Modular Neural Network is a neural system composed of multiple smaller neural networks that work independently on subtasks and then combine their outputs to solve a larger problem. This modular approach improves scalability, flexibility, and fault tolerance because each module specializes in a specific function. Modular neural networks are used in robotics, complex decision-making systems, autonomous systems, and large-scale AI architectures. Their major features include parallel processing, specialization of modules, scalability, and reduced system complexity.
Why Deep Learning Became So Popular
Deep learning became extremely popular because several technological and industrial developments happened together at the right time. These developments helped neural networks become more practical, more powerful, and easier to use in real-world applications.
The major factors behind the success of deep learning are:
- Availability of Massive Datasets
- Improvement in Hardware
- Better Neural Network Architectures
- Development of Deep Learning Frameworks
- Open Source Research Community
- Exceptional Real-World Performance
Availability of Massive Datasets
One of the biggest reasons behind the success of deep learning was the explosion of digital data. Deep learning algorithms are highly data hungry, which means they require very large amounts of training data in order to learn patterns effectively.
After smartphones, social media platforms, cloud computing, and cheap internet access became common, humans started generating enormous amounts of data every day in the form of photos, videos, text messages, audio recordings, and online interactions.
Large technology companies such as Google, Microsoft, and Facebook collected and organized this information into large datasets. Many of these datasets were later released publicly, allowing researchers around the world to train powerful deep learning models.
Without large datasets, modern deep learning systems would not have achieved their current level of accuracy and performance.
Improvement in Hardware
Deep learning models perform extremely large mathematical computations, especially matrix multiplications involving millions of numbers. Training such models on normal CPUs was very slow and inefficient.
The introduction of GPUs (Graphics Processing Units) changed this completely. GPUs are capable of performing many calculations simultaneously using parallel processing, making them ideal for neural network training.
As hardware improved, researchers were able to train deeper and larger neural networks much faster. Later, specialized AI hardware such as TPUs (Tensor Processing Units) and NPUs (Neural Processing Units) were also developed specifically for deep learning workloads.
This massive increase in computational power accelerated deep learning research significantly.
Better Neural Network Architectures
Earlier neural networks were relatively simple and not powerful enough for complex real-world tasks. Over time, researchers developed advanced neural network architectures capable of solving highly specialized problems.
For example:
- Convolutional Neural Networks (CNNs) became highly successful for image processing.
- Recurrent Neural Networks (RNNs) improved speech and sequential data processing.
- Transformers revolutionized natural language processing and modern AI systems.
These architectural improvements dramatically increased the accuracy and capabilities of deep learning systems across multiple industries.
Development of Deep Learning Frameworks
Building neural networks from scratch is extremely difficult because it involves complex mathematical operations, optimization algorithms, and gradient calculations.
Deep learning frameworks such as:
- TensorFlow
- PyTorch
- Keras
made development much easier by providing ready-made tools and libraries for building, training, and deploying neural networks.
These frameworks reduced the complexity of implementation and allowed developers to focus more on solving real-world problems rather than writing low-level mathematical code.
As a result, deep learning became accessible to students, researchers, and software engineers worldwide.
Open Source Research Community
The growth of the open-source AI community also played a major role in the popularity of deep learning. Researchers and organizations started openly sharing:
- research papers
- source code
- datasets
- pretrained models
- tutorials
This collaborative environment allowed people around the world to learn from each other and improve existing models rapidly.
Instead of every company building everything independently, researchers could build on top of previous work, which accelerated innovation tremendously.
Exceptional Real-World Performance
Deep learning became extremely popular because it produced outstanding results in real-world applications. In many domains, deep learning systems achieved state-of-the-art performance and sometimes even surpassed human experts.
Deep learning showed remarkable success in fields such as:
- image recognition
- speech recognition
- machine translation
- autonomous driving
- medical diagnosis
- recommendation systems
- natural language processing
For example, deep learning models became capable of recognizing objects in images with very high accuracy, understanding spoken language, and generating human-like text.
This combination of broad applicability and high performance made deep learning one of the most important technologies in modern Artificial Intelligence.