ClickHouse - An Introduction
Modern applications generate data at an extraordinary rate. Every user interaction, application log, sensor reading, financial transaction, website click, and monitoring event contributes to an ever-growing volume of information. While traditional relational databases are excellent for handling transactional workloads, they often struggle when organizations need to analyze massive datasets containing billions or even trillions of records.
This is where ClickHouse enters the picture. ClickHouse is a high-performance, column-oriented database management system designed specifically for Online Analytical Processing (OLAP) workloads. It is optimized for executing complex analytical queries on enormous datasets while delivering results in milliseconds or seconds.
The popularity of ClickHouse has grown rapidly because it enables organizations to store petabytes of data and perform real-time analytics without requiring expensive proprietary data warehouse solutions. Today, ClickHouse is widely used for log analytics, observability platforms, business intelligence dashboards, telemetry systems, financial analytics, and many other data-intensive applications.
This tutorial introduces ClickHouse, explains its architecture and design philosophy, discusses its strengths and limitations, and helps you understand when it should and should not be used.
The History of ClickHouse
Understanding the origin of a technology often provides valuable insight into the problems it was designed to solve.
ClickHouse was originally developed inside the company Yandex for its web analytics platform called Yandex Metrica. The development began because Yandex needed a database capable of processing extremely large volumes of analytical data while maintaining very fast query performance.
The system entered production use around 2012 and was continuously improved to meet the demanding requirements of Yandex's analytics infrastructure. After several years of successful internal usage, ClickHouse was open-sourced in 2016, allowing developers and organizations worldwide to benefit from the technology. Later, a dedicated company, ClickHouse, was formed to drive its development, support, and ecosystem growth.
One of the most impressive demonstrations of ClickHouse's capabilities came from Yandex itself. By 2020, Yandex Metrica was operating some of the largest ClickHouse clusters in existence. These deployments consisted of hundreds of nodes, petabytes of storage, and hundreds of trillions of records. Such large-scale deployments demonstrated that ClickHouse was capable of handling data volumes that many traditional databases would find extremely challenging.
Why Was ClickHouse Created?
Traditional databases were primarily designed for transactional systems.
Consider a banking application. Typical operations include:
- Creating accounts
- Updating balances
- Processing transactions
- Maintaining strict consistency
These operations involve frequent inserts, updates, and deletes.
Analytical systems have very different requirements. Instead of updating a few records, analysts may need to:
- Scan billions of rows
- Aggregate large datasets
- Calculate metrics and trends
- Generate reports and dashboards
- Perform real-time business analytics
A database optimized for transactions is not necessarily optimized for analytics. ClickHouse was designed specifically for analytical workloads where the primary goal is reading and analyzing large volumes of data as quickly as possible.
Understanding Column-Oriented Storage
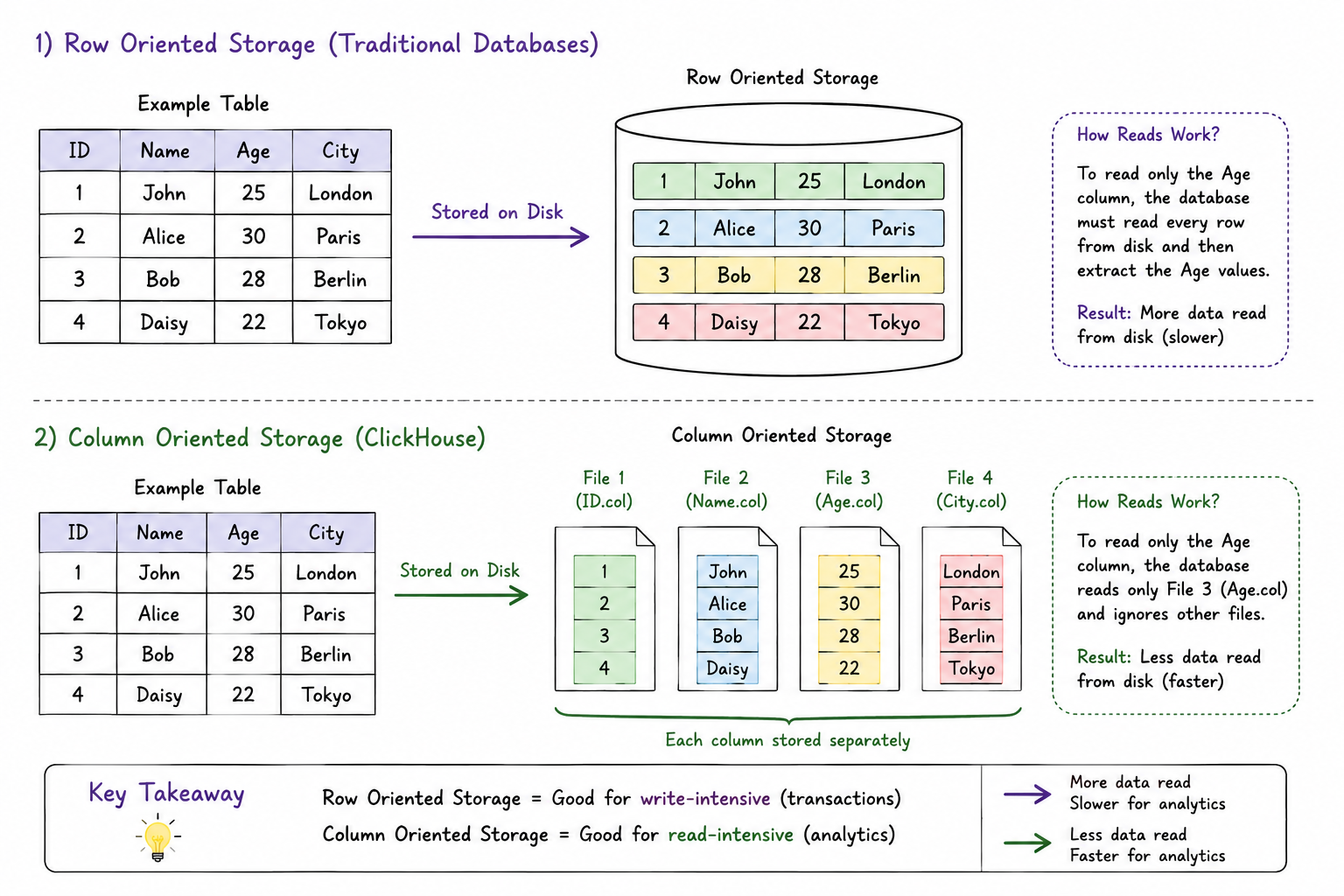
The most important concept in ClickHouse is its columnar storage architecture.
Although ClickHouse stores data in tables consisting of rows and columns, similar to relational databases, the physical storage mechanism is completely different.
To understand this difference, let us first examine how traditional databases store data.
Row-Oriented Storage
Most transactional databases such as:
- MySQL
- PostgreSQL
- Oracle Database
use row-oriented storage.
In a row-oriented database each complete row is stored together. When a query requests only the Age column, the database still needs to read the entire row structure from disk before extracting the required values. This approach works very well for transactional systems because transactions usually operate on complete rows.
Column-Oriented Storage
ClickHouse uses a column-oriented storage model. Instead of storing complete rows together, each column is stored independently. Conceptually, each column behaves like an independent data stream.
When a query requires only the Age column:
SELECT AVG(Age)
FROM users;
ClickHouse reads only the Age data rather than scanning all columns. This significantly reduces disk I/O and improves query performance.
Why Columnar Storage Is Fast
The performance advantage of ClickHouse comes from several factors.
Reading Only Required Columns
Analytical queries often access only a small subset of available columns.
For example:
SELECT
country,
SUM(revenue)
FROM sales
GROUP BY country;
If the table contains 100 columns, only two columns are actually required. A row-oriented database may read all 100 columns. ClickHouse reads only country, revenue. This dramatically reduces the amount of data read from storage.
Better Compression
Column data usually contains similar values.
For example:
Country
India
India
India
India
India
Since values are similar, compression algorithms achieve much higher compression ratios.
Benefits include:
- Reduced storage usage
- Faster disk reads
- Lower network transfer costs
- Better cache utilization
ClickHouse is well known for achieving excellent compression while maintaining very high query speeds.
Vectorized Processing
Since values of the same type are stored together, ClickHouse can process data in batches rather than one row at a time.
Instead of:
- Process Row 1
- Process Row 2
- Process Row 3
it can process:
Process 10,000 values together
This makes better use of CPU caches and modern processor instructions.
Key Features of ClickHouse
ClickHouse offers numerous features that make it attractive for analytical systems.
High-Speed Analytical Queries
The primary objective of ClickHouse is fast analytical processing.
Queries involving:
- Aggregations
- Filtering
- Grouping
- Time-series analysis
can often be executed in milliseconds even on extremely large datasets.
SQL Support
ClickHouse supports SQL and provides a syntax that is familiar to developers who have worked with relational databases.
For example:
SELECT
region,
COUNT(*)
FROM orders
GROUP BY region;
The SQL dialect includes many built-in analytical functions that simplify complex reporting requirements.
Replication Support
Data replication helps ensure availability and fault tolerance. If one server fails, replicas can continue serving requests, minimizing downtime and reducing the risk of data loss.
Horizontal Scalability
ClickHouse supports sharding, allowing data to be distributed across multiple servers. As data volume grows the cluster can continue scaling to meet increasing storage and processing demands.
Distributed Query Processing
When data is distributed across multiple nodes, ClickHouse can execute queries in parallel. Each node processes its portion of the data, and the results are combined to produce the final output. This enables efficient processing of massive datasets.
Integration with External Systems
One of ClickHouse's strengths is its rich ecosystem of integrations.
For example, it can work with:
- MySQL
- PostgreSQL
- Apache Kafka
- Amazon Web Services S3 storage
This flexibility allows organizations to integrate ClickHouse into existing data architectures without significant redesign.
Strengths of ClickHouse
Before choosing any database, it is important to understand its ideal use cases.
Massive Scale Analytics
ClickHouse excels at storing and querying:
- Billions of rows
- Trillions of rows
- Petabytes of data
Many organizations use it as the analytical backbone of their data platforms.
Excellent Read Performance
ClickHouse is optimized for analytical reads.
Queries involving:
GROUP BY
SUM()
AVG()
COUNT()
MIN()
MAX()
are typically executed extremely efficiently.
Wide Tables
Unlike many systems that struggle with large numbers of columns, ClickHouse performs well with tables containing hundreds of columns.
Efficient Compression
Data compression reduces storage costs while improving performance.
Because columns contain similar data types and values, ClickHouse can achieve impressive compression ratios.
When ClickHouse Is Not a Good Choice
Although ClickHouse is an exceptionally powerful analytical database, it is important to remember that it was designed with a very specific set of goals in mind. Many teams encounter difficulties after adopting ClickHouse because they assume it can replace every other type of database in their architecture. In reality, ClickHouse excels in analytical workloads but may not be the best solution when the application requirements are centered around transactions, frequent updates, complex relationships, or strict consistency guarantees.
Understanding these limitations before designing a system can save significant effort later and help ensure that the chosen database aligns with the workload's characteristics.
Applications with Frequent Updates and Deletes
ClickHouse performs best when data is written once and queried many times afterward. If your application frequently updates existing records or continuously deletes and modifies data, ClickHouse may not be the ideal choice.
OLTP Systems Requiring ACID Transactions
Many business applications depend heavily on transactional guarantees. In such systems, multiple operations must either succeed together or fail together to maintain data integrity.
For example, a banking transfer may involve:
- Deducting money from one account.
- Adding money to another account.
- Recording the transaction history.
If any of these operations fail midway, the entire transaction must be rolled back to prevent inconsistent data.
Traditional relational databases such as PostgreSQL, MySQL, and Oracle were specifically designed for these requirements and provide strong ACID guarantees. ClickHouse, on the other hand, focuses on analytical processing and does not provide the same level of transactional capabilities that OLTP applications typically require.
As a result, systems such as banking applications, payment gateways, order processing systems, and reservation platforms are generally better served by transactional databases.
Applications with Complex Relational Models
Many enterprise applications are built using highly normalized database designs. In these systems, information is distributed across multiple related tables to reduce redundancy and maintain consistency.
For example, an e-commerce platform might have separate tables for:
- Customers
- Orders
- Order Items
- Products
- Categories
- Suppliers
Generating reports often requires joining these tables together.
Although ClickHouse supports joins, it is primarily optimized for large-scale analytical scans and aggregations rather than complex relational operations. Queries involving multiple large joins may not perform as efficiently as they would in databases specifically optimized for relational workloads.
For this reason, ClickHouse often encourages denormalized data models where related information is combined into fewer, wider tables. If your application depends heavily on normalized schemas and complex join operations, a traditional relational database may provide a more natural and efficient solution.
Systems Requiring Strong Consistency Across Nodes
In distributed environments, some applications require all users to see exactly the same data at the same time, regardless of which server handles the request.
For example:
- Financial trading platforms
- Payment processing systems
- Critical inventory systems
- Reservation systems for flights or hotels
These applications often require strong consistency guarantees because even a small delay in synchronization can lead to incorrect business decisions or financial losses.
ClickHouse uses an eventual consistency model for replication. This means that updates are propagated to replicas over time rather than becoming instantly visible everywhere. While this approach improves scalability and availability, it may not be appropriate for systems where every read must immediately reflect the latest write.
Workloads with Thousands of Small Concurrent Transactions
Transactional databases are optimized to handle large numbers of small, independent operations occurring simultaneously. A typical web application may have thousands of users performing actions such as:
- Logging in
- Updating profiles
- Adding products to carts
- Changing account settings
- Submitting forms
Each operation typically affects only a few rows and requires a quick transactional response.
ClickHouse is designed for a different workload pattern. It is optimized for scanning large datasets and performing analytical computations rather than processing vast numbers of tiny transactions. While it can handle concurrent analytical queries efficiently, it is not intended to serve as the primary transactional database for highly interactive applications.
Small Datasets with Simple Reporting Requirements
Not every project needs a specialized analytical database.
Suppose an application stores only a few million records and generates a handful of reports each day. In such cases, a traditional relational database may already provide excellent performance without introducing additional infrastructure complexity.
Deploying ClickHouse for relatively small datasets can sometimes add operational overhead without delivering significant benefits. Before introducing another technology into the architecture, it is worth evaluating whether the existing database can already satisfy the analytical requirements.